
티스토리 뷰
「텍스트 파일을 불러와서 일정한 부분을 기준으로 자르거나 필요없는 내용을 지워보겠습니다.」
지우기 위한 순서를 간단히 다타내면 다음처럼 되겠군요!
- txt파일을 불러옵니다.
- 원하는 방식으로 나눕니다
- 쓸데 없는 부분을 자릅니다.
- 그 내용을 저장하거나 덮어 씌웁니다.
첫 번째로 txt파일을 불러오는 코드는 다음과 같습니다.
#filename이라는 이름의 txt파일 불러옴
with open('filename.txt', 'rt', encoding='UTF8') as data:
liness = data.readlines()이 부분에선 filename이라는 이름의 txt파일을 불러 왔군요! 'rt'는 read권한을 모두 준다는 뜻이고, encoding='UTF8'은 말 그대로 인코딩 방식으로 UTF8을 사용한다는 뜻입니다. data.realines의 의미는 저 txt파일을 줄별로 한 줄씩 나눠서 받는 다는 의미입니다. 줄로 나눠서 받기 때문에 liness는 배열로 저장 되겠군요
다음은 liness로 저장한 후 출력한 모습입니다.
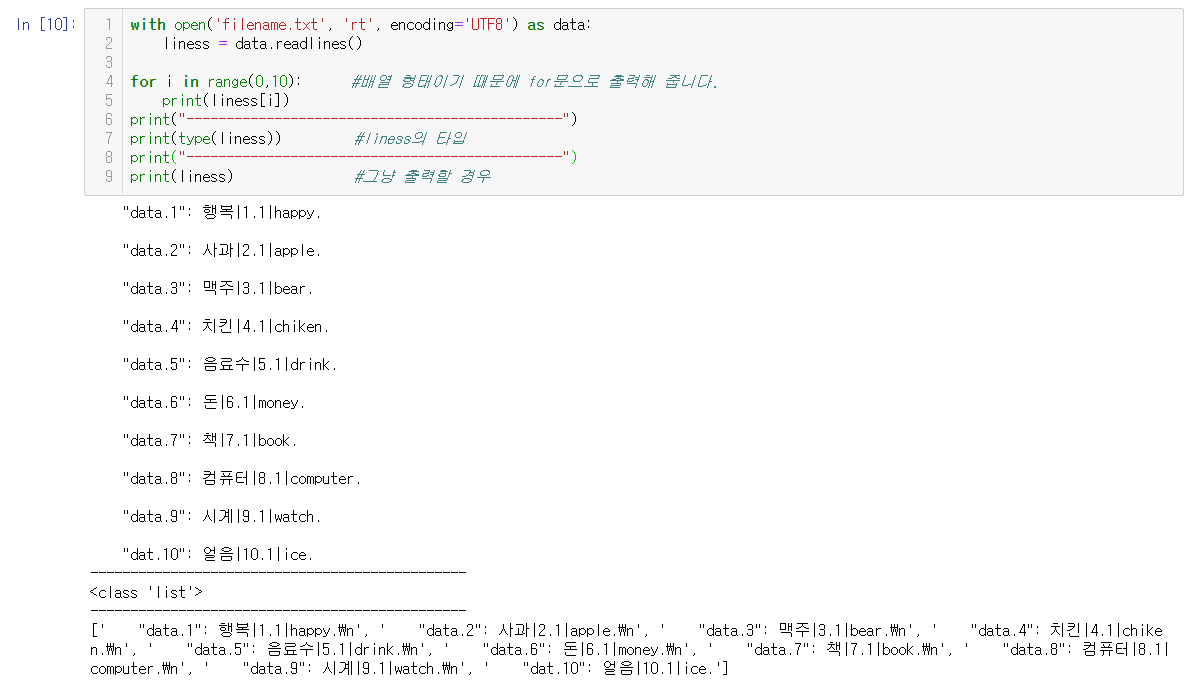
두 번째로 해당 줄의 특정한 부분을 기준으로 자르는 코드는 다음과 같습니다.
#줄이 10개일 때를 가정한 상태입니다.
for i in range(0,10):
liness[i] = liness[i].split("|", 1) #몇 번째 '|'를 기준으로 자를 것인지를 정하는데
#이번엔 1이므로 첫번째 '|'를 기준으로 자릅니다.다음은 이 코드를 추가해 본 결과입니다.

사진을 보면 첫번째 | 를 기준으로 두가지로 잘린 것을 볼 수 있습니다.
세번째로 자른 텍스트 중 필요없는 부분을 버리는 코드입니다.
총 두가지 방법이 있는데
첫번째 방법은 liness의 각 첫번째 것만 가져와 liness에 덮어씌우는 방법이고, 두번째 방법은 liness를 뒤에서부터 1칸 앞을 기준으로 뒷 배열을 잘라버리는 것입니다.
- 1번 방법
liness[i] = liness[i][0]
- 2번 방법
liness[i] = liness[i][:-1]1번 방법으로 뽑았을때:

2번 방법으로 뽑았을 때:

차이점이 보이시나요?
「 1번 방법으로 뽑았을 때에는 대괄호가 1개인 형태로 뽑혔고,
2번 방법으로 뽑았을 때에는 대괄호가 2개인 형태로 뽑혔네요!」
왜 이런 차이가 날까요? 그 이유는 1번에서 사용한 liness[i][0]방식은 liness[i]의 첫번째 요소를 가져오는 느낌입니다. 반면에 2번에서 사용한 liness[i][:-1]방식은 liness[i]의 마지막 데이터를 잘라내는 느낌이므로 liness[i][:-1]의 값이 리스트의 형태로 나오게 되면서 liness를 출력하니 리스트 안의 리스트 형태로 출력 되는 것입니다! 뭐 일단 지금 쓸 글에서는 이 차이점을 자세하게 다루지 않으니 빨리 넘어가자구요.
네 번째는 행복,사과 같은 단어만 추출하기 위해서 앞 부분을 자르는 코드입니다.
liness[i] = liness[i][14:]14의 의미는 앞에 쓸데없는 13글자를 자른다는 의미입니다.

자 깔끔하게 원하는 단어만을 출력할 수 있게 되었습니다. 다음 글에서는 if문을 활용하여 일부 문장에 쓸데없는 기호들을 자르는 방법과 이 출력 결과를 txt파일로 저장하는 방법까지 소개하겠습니다.
'프로그래밍 > python' 카테고리의 다른 글
| [Python] 원하는 텍스트 출력하기 - print() (0) | 2020.02.13 |
|---|---|
| [Python] 특정 문장 반복해 출력,저장하기 (0) | 2020.02.07 |
| [python]필요없는 특수문자,내용 자르기 (0) | 2020.01.23 |
| [python]txt메모장에서 원하는 text만 뽑고 메모장에 저장하기 (0) | 2020.01.21 |
| [python] pytesseract를 사용해서 글씨 인식시키기 (2) | 2020.01.19 |
- Total
- Today
- Yesterday
- JavaScript
- 2022.02.05
- django
- Python
- localstorage
- promise반환
- 1254
- 꿈두레
- 문제풀이
- 주석
- 도전
- 바닐라 javascript
- Codeup
- 크롤링
- Anaconda
- 코드설명
- 컨트롤타임
- 티처블 머신
- 사칙연산
- pygame
- 아나콘다
- 1251
- 바닐라 js
- 1255
- 1252
- 타이탄의도구들
- notion api
- SMTP
- 코드업
- 1253
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |