
티스토리 뷰
「 이번에는 책 정보를 가져와 해당 정보(저자, 출판사, 가격)를
이메일로 보내는 코드를 포스팅하겠습니다.」
이론 설명:
1. 빨간색 네모 앞부분을 보면 일정 url뒤에 책 제목을 입력하면 네이버에 직접 검색한 것과 같은 결과를 얻을 수 있는 것을 확인 가능한데, 저 규칙을 이용하여 책 정보를 가져옵니다.
2. 필요한 정보는 저 주황색 네모 안의 노란색, 초록색, 파란색 네모 속 저자, 출판사, 가격으로 크롤링을 통해 데이터를 가져옵니다.
3. 가져온 데이터를 replace, split 등을 사용하여 가공해 줍니다.
4. smtp(Simple Mail Transfer Protocol/간단 메일 전송 프로토콜)을 이용해 해당 내용을 email로 보내줍니다.

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
# -*- coding:utf-8 -*-
import smtplib
from email.mime.text import MIMEText
import requests
from bs4 import BeautifulSoup
try:
data = []
text = "화이트 해커를 위한 암호화 해킹"
test_url = "https://search.naver.com/search.naver?sm=top_hty&fbm=1&ie=utf8&query=" + text
resp = requests.get(test_url)
html = BeautifulSoup(resp.content, 'html.parser')
score_result = html.find('div', {'class': 'book_list section'})
lis = score_result.findAll('em')
price = str(lis)
price = price.split(">", 2)
price = price[1]
price = price.split("(", 1)
price = price[0]
score_result = html.find('li', {'class': 'sh_book_top'})
for i in score_result.select('dd[class=author]'):
data.append(i.text)
data = str(data)
writer = data.split("저", 1)
comp = writer[1]
comp = comp.split("2", 1)
comp = comp[0]
comp = comp.lstrip()
writer_f = writer[0]
writer_f = writer_f.replace("['","")
str_f = "작가 : " + writer_f + " 출판사 : " + comp + " 가격 : " + price
print(str_f)
str_f = str(str_f)
text = str(text)
smtp = smtplib.SMTP('smtp.live.com', 587)
smtp.ehlo() # say Hello
smtp.starttls() # TLS 사용시 필요
smtp.login('보낼 사람의 microsoft 이메일', '그 이메일의 비밀번호')
msg = MIMEText(str_f)
msg['Subject'] = text #제목
msg['To'] = '받을 사람의 일반 이메일 ex)----@naver.com'
smtp.sendmail('보낼 사람의 microsoft이메일', '받을 사람의 이메일', msg.as_string())
smtp.quit()
print("전송 완료")
except:
print("오류가 발생했습니다!")
|
cs |
2~4번 줄 : 필요한 라이브러리를 불러옵니다. (없으시다면 설치해주세요! pip install로 설치 가능합니다)
7 번 줄 : 60번 줄과 함께 모든 에러를 예외 처리해줍니다. (해당 제목이 없거나 검색해 찾을 수 없으면)
9 번 줄 : 책 제목을 text라는 변수에 넣어줍니다.
10 번 줄 : 네이버의 검색 url에 text(책 제목)을 합쳐줍니다. (그 책 제목으로 검색한 것과 같은 결과가 나옵니다.)
11~15 줄 : 정보를 가져오는 내용입니다.
17~22 줄 : 책의 가격을 가져와 price변수에 저장합니다.
24~37 줄 : 책의 작가, 출판사를 각각 writer_f, comp에 저장합니다.
40 번 줄 : 가져온 모든 정보를 str_f에 저장합니다.
45~56 줄 : 해당 정보를 이메일로 전송합니다.
58 번 줄 : 성공적으로 전송되었다면 "전송 완료"라는 문구를 출력합니다.
60 번 줄 : 오류 발생 시 "오류가 발생했습니다"라는 문구를 출력합니다.
실행 결과:
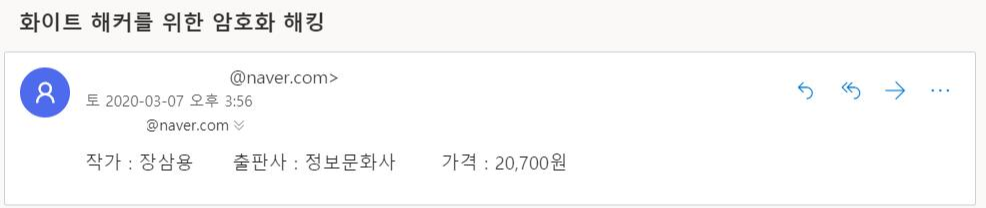
Microsoft 이메일로 로그인하시면 성공적으로 보내진 것을 확인하실 수 있습니다!
※해당 사이트의 robots.txt를 찾아보면
User-agent: * Disallow: /search
이므로 이 포스팅은 공부 참고용으로만 사용해주시기를 권장합니다! ※
'프로그래밍 > 프로젝트' 카테고리의 다른 글
| [APi프로젝트] 구글 클래스룸API 활용 서비스 개발 (0) | 2021.02.27 |
|---|---|
| [Python] webdriver으로 네이버 지도 가져오기 (0) | 2020.03.09 |
| [Python][IFTTT]코로나 현황을 크롤링해 메세지로 전송해보기 (9) | 2020.02.27 |
| [python] Tacotron 간단 구현 후기 (2) | 2020.02.16 |
- Total
- Today
- Yesterday
- 꿈두레
- 주석
- django
- JavaScript
- 바닐라 javascript
- 1253
- Codeup
- 문제풀이
- 코드설명
- 티처블 머신
- Anaconda
- 코드업
- 도전
- 1254
- 아나콘다
- notion api
- 1255
- pygame
- 2022.02.05
- 컨트롤타임
- 1251
- 1252
- SMTP
- 크롤링
- promise반환
- 타이탄의도구들
- Python
- localstorage
- 사칙연산
- 바닐라 js
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |